Aperçu d'Unicode
Vous trouverez ici des détails sur la gestion des informations dans Unicode.
Points de code
L'unité d’information de base dans Unicode est le point de code. Un point de code est simplement un nombre compris entre zéro et 10FFFF16 qui représente une entité unique. Les points de code sont généralement représentés sous forme de nombres hexadécimaux, c'est-à-dire en base 16. Une entité peut être l'un des éléments suivants :
| Entité | Description |
|---|---|
| graphique |
Une lettre, une marque, un chiffre, une ponctuation, un symbole ou un espace, par exemple la lettre |
| format |
Contrôle la mise en forme du texte, par exemple le tiret ( |
| contrôle |
Un caractère de contrôle, par exemple le caractère de tabulation ( |
| utilisation privée |
Non défini dans le standard Unicode 8.0 mais utilisé par d'autres scripts non-Unicode, par exemple le caractère inutilisé cp 1252, 9116. |
| substitut |
Utilisé pour sélectionner des plans supplémentaires en UTF-16. Caractères dans la plage D800-DFFF16. |
| non caractère |
Réservé en permanence à l'utilisation interne. Caractères dans la plage FFFE-FFFF16 et FDD0-FDEF16. |
| réservé |
Tous les points de code non attribués, c'est-à-dire les points de code qui ne font pas partie des points ci-dessus. |
Le tableau ci-dessous recense quelques points de code avec leur représentation, leur étiquette et leur catégorie :
| Point de code (hex) | Représentation | Intitulé | Catégorie |
|---|---|---|---|
|
E9 |
é |
Minuscule Latin e avec accent aigu |
graphique (lettre - minuscule) |
|
600 |
|
Chiffre arabe |
format (autre) |
|
D6A1 |
횡 |
Syllabe hangul hoeng |
graphique (lettre - autre) |
|
B4 |
´ |
Accent aigu |
graphique (symbole - modificateur) |
|
F900 |
豈 |
Idéogramme de compatibilité chinois, japonais, coréen (cjk) |
graphique (lettre - autre) |
Un morceau de texte n'est logiquement qu'une séquence de points de code, où chaque point de code représente une partie du texte. Par exemple, le morceau de texte :
豈 ↔ how?
se compose des points de code suivants :
| Point de code (hex) | Représentation | Intitulé |
|---|---|---|
|
F900 |
豈 |
Idéogramme de compatibilité chinois, japonais, coréen (cjk) |
|
20 |
|
Espace |
|
2194 |
↔ |
Flèche gauche-droite |
|
20 |
|
Espace |
|
68 |
h |
Minuscule Latin h |
|
6F |
o |
Minuscule Latin o |
|
77 |
w |
Minuscule latine w |
|
3F |
? |
Point d'interrogation |
La séquence de points de code définit le texte lui-même. Il existe plusieurs façons de sauvegarder la séquence de points de code sur un ordinateur. Une méthode, appelée UTF-32, représente chaque point de code comme égal à 32 bits (4 octets). Un tel système requiert une grande quantité d'espace de stockage car la plupart du texte utilise l'alphabet latin (ASCII), qui peut être représenté par un seul octet.
Un autre encodage est UTF-8. Il permet de stocker les caractères ASCII sur un seul octet (points de code 00-7F), plusieurs octets étant utilisés pour les points de code supérieurs. UTF-8 est très efficace en termes d'espace lorsque le texte se compose principalement de caractères ASCII. Internet l'a adopté comme méthode d'encodage préférée pour les points de code Unicode. EMu utilise également UTF-8 comme méthode d'encodage. Retrouvez ci-dessous une chaîne de caractères codée en UTF-32 avec un espace entre chaque point de code :
豈 ↔ how?
0000F900 00000020 00002194 00000020 00000068 0000006F 00000077 0000003F
Et la même chaîne encodée en UTF-8 :
EFA480 20 E28694 20 68 6F 77 3F
Comme vous pouvez le constater, l’UTF-8 permet un gain d'espace considérable.
Avant EMu 5.0, les méthodes d’encodage possibles étaient UTF-8 ou ISO-8859-1. EMu 5.0 ne prend plus en charge ISO-8859-1 et ne prend en charge que les caractères encodés en UTF-8. Ce changement implique que pour passer à EMu 5.0, la conversion de toutes les données d'ISO-8859-1 en UTF-8 est requise avant de pouvoir utiliser le système. Le processus de mise à niveau effectue cette tâche importante.
Saisie de caractères Unicode
Maintenant que nous savons que le texte est constitué d'une séquence de points de code Unicode, regardons comment saisir ces caractères dans EMu.
Le mécanisme de point de code échappé permet de placer une séquence d'échappement dans une chaîne de texte pour représenter un point de code Unicode. Lorsque la chaîne est envoyée au serveur EMu, la séquence d'échappement est convertie en un point de code Unicode encodé en UTF-8.
Par exemple, si le texte Fr\u{E9}deric a été saisi lors de la création ou de la modification d'un enregistrement, les données enregistrées seront Fréderic. Le format de la séquence d'échappement est le suivant : \u{x} où x est le point de code en hexadécimal du caractère Unicode requis. La séquence d'échappement peut également être utilisée lors de la saisie des termes de recherche :
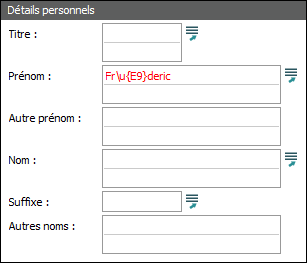
La séquence d'échappement peut également être utilisée dans les déclarations texql lorsqu'une constante de chaîne est requise. Par exemple, la déclaration de requête :
sélectionnez NamFirst
depuis eparties
où NamFirst contient 'Fr\u{E9}deric'.
trouvera tous les enregistrements Personnes / Organisations où le Prénom est Fréderic (et les variantes où les diacritiques sont ignorés). Le format de séquence d'échappement peut également être utilisé pour les données importées dans EMu via la fonction Importer.
La méthode des caractères bruts consiste à coller des caractères Unicode dans le champ EMu requis. Il existe de nombreuses façons d'ajouter des caractères Unicode au presse-papier de Windows. Vous pouvez par exemple utiliser la Table de caractères de Windows. Ouvrez-la sur un PC Windows en sélectionnant Recherche dans le menu Démarrer de Windows (ou en appuyant simultanément sur la touche Logo Windows et s) et en recherchant charmap.
Avec l'application Table de caractères de Windows, il est possible de sélectionner un caractère et de le copier dans le presse-papier. En sélectionnant Affichage avancé, il est possible de rechercher un caractère par son nom. Par exemple, pour trouver le caractère de ligature oe (œ), saisissez oe ligature dans le champ Rechercher : et cliquez sur Rechercher. Une grille de tous les caractères correspondants s'affiche :

Double-cliquez sur le caractère requis, puis cliquez sur Copier pour le placer dans le presse-papier de Windows. Le caractère peut ensuite être collé dans EMu.
Une autre façon d'ajouter un caractère Unicode au presse-papier de Windows est d'utiliser un site permettant de rechercher et d'afficher les caractères Unicode. Voici deux sites utiles :
Avec ces deux sites, il est possible de rechercher un caractère par son nom ou son point de code (en hexadécimal), par exemple :

Mettez le caractère en surbrillance sur la page et copiez-le dans le presse-papier. Le caractère peut ensuite être collé dans le champ EMu requis.
Ces deux sites Web affichent le point de code du caractère. Dans l'image ci-dessus, le point de code pour œ est hex 153. Si vous vouliez utiliser la méthode des points de code échappés, la séquence d'échappement à utiliser serait la suivante :
\u{153}
Tip: Si vous devez régulièrement saisir certains caractères Unicode, vous pouvez créer un document WordPad (ou Word) contenant ces caractères. Lorsque vous avez besoin d'un caractère, il suffit de copier le caractère du document et de le coller dans EMu, sans avoir à le rechercher.
Graphèmes
Il est important de comprendre que ce que nous considérons comme un caractère, c'est-à-dire une unité d'écriture de base, peut ne pas être représenté par un seul point de code Unicode. Au contraire, cette unité de base peut être constituée de plusieurs points de code Unicode.
Par exemple, « g » + accent aigu (ǵ) est un caractère perçu par l'utilisateur car nous le considérons comme un caractère unique, mais il est constitué de deux points de code Unicode (67 301). Un caractère perçu par l'utilisateur, qui consiste en un ou plusieurs points de code, est appelé graphème. L'utilisation des graphèmes est importante pour :
- la collation (tri) ;
- les expressions régulières ;
- l'indexation ; et
- compter les positions des caractères dans le texte.
EMu utilise les graphèmes comme élément de construction de base du texte. Ainsi, une chaîne de texte est gérée comme une séquence de graphèmes.
Un graphème est constitué d'un ou plusieurs points de code de base suivis d'un ou plusieurs points de code sans chasse et d'un ou plusieurs points de code de marque de non-espacement. Dans le cas de « g » + accent aigu (ǵ), la lettre g est le point de code de base (67) et l’accent aigu un point de code de marque de non-espacement (301). Le tableau ci-dessous présente quelques graphèmes à points de code multiples :
| Graphème | Points de code |
|---|---|
|
각 |
1100 (ᄀ) Hangul choseong kiyeok (point de code de base) 1161 (ᅡ) Hangul jungseong a (point de code de base) 11A8 (ᄀ) Hangul jongseong kiyeok (point de code de base) |
|
|
64 (d) Minuscule Latin d (point de code de base) 325 ( ̥ ) Rond souscrit combiné (marque de non-espacement) 301 ( ́ ) Accent aigu combiné (marque de non-espacement) |
|
á |
61 (a) Minuscule Latin a (point de code de base) 301 ( ́ ) Accent aigu combiné (marque de non-espacement) |
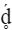
Certains graphèmes communs à plusieurs points de code ont été combinés en un point de code unique. Par exemple, la dernière entrée du tableau ci-dessus, á, peut également être représentée par le point de code unique E1. Nous avons donc deux représentations, ou deux graphèmes, qui représentent le même caractère (á dans ce cas).
Termes d'index
Un terme d'index est l'unité de base pour la recherche. Il s'agit d'une séquence d'un ou plusieurs graphèmes qui peut être trouvée lors d'une recherche mais pour laquelle la recherche de sous-parties n'est pas prise en charge (sauf si des expressions régulières sont utilisées). EMu fournit une recherche par mots : un terme d'index correspond donc à un mot. Vous pouvez rechercher un mot, et les enregistrements contenant ce mot seront renvoyés. Dans les langues qui définissent un mot comme une séquence de lettres séparées par des espaces ou une ponctuation, un terme d'index correspond à un mot. Dans les langues où une seule (ou parfois plusieurs) lettre(s) composent un mot, comme les kanji, un terme d'index correspond à chaque lettre individuelle. EMu 5.0 a ajouté la prise en charge de la recherche de ponctuation. Ainsi, chaque caractère de ponctuation est considéré comme un terme d'index.
Observez le texte suivant :
香港 is Chinese for "Hong Kong" (香 = fragrant, 港 = harbour).
Les termes d'index pour le texte ci-dessus sont :
| Terme d’index |
|---|
|
香 |
|
港 |
|
est |
|
Chinois |
|
pour |
|
" |
|
Hong |
|
Kong |
|
" |
|
( |
|
香 |
|
= |
|
parfumé |
|
, |
|
港 |
|
= |
|
port |
|
) |
|
. |
Chacun des termes ci-dessus peut être utilisé dans une recherche et la requête sera en mesure d'utiliser les index rapides pour localiser les enregistrements correspondants. Il est possible d'utiliser des caractères d'expression régulière (par exemple fra\* pour trouver tous les mots commençant par fra) pour rechercher des sous-parties de mots, mais les index rapides ne seront pas utilisés dans ce cas (sauf si l'indexation partielle est activée).
Chaque terme d'index est plié et converti dans sa forme de base. Le processus de non-sensibilité à la casse, tel que décrit plus tôt, enlève toute signification de la casse à ce terme. La conversion dans sa forme de base implique la suppression de tous les points de code de « marque » du terme, puis la conversion des points de code restants dans leur forme compatible (telle que définie par le standard Unicode 8.0). La forme compatible d'un point de code est une correspondance entre le point de code actuel et un caractère de base qui a la même signification. Par exemple, le point de code de l'indice 5 (5) a un point de code compatible de 5.
Le tableau ci-dessous présente d'autres exemples de compatibilité :
| Type | Exemples de compatibilité | ||
|---|---|---|---|
|
Variantes de polices |
H | à | H |
| H | à | H | |
|
Variantes de position |
ع | à | ع |
| ﻊ | à | ع | |
| ﻋ | à | ع | |
| ﻌ | à | ع | |
|
Variantes cerclées |
| à | 1 |
|
Variantes de largeur |
カ | à | カ |
|
Variantes pivotées |
︷ | à | { |
| ︸ | à | } | |
|
Exposants / indices |
i9 | à | i9 |
| i9 | à | i9 | |
Malheureusement, certaines correspondances de compatibilité dans le standard Unicode 8.0 sons plus restreintes que ce à quoi on pourrait s'attendre lors d'une recherche de texte. Par exemple, la ligature oe (œ) ne correspond pas aux caractères « oe ». Ainsi, le mot français cœur n'a pas coeur comme terme d'index, mais reste comme cœur. Lorsque vous effectuez une recherche, vous devez saisir cœur comme terme de recherche, sinon vous ne trouverez pas « cœur ».
Afin de corriger certaines correspondances de compatibilité, EMu 1 fournit un fichier de correspondance dans lequel un point de code peut être mappé avec son ou ses points de code compatibles. Ainsi, « œ » peut être mappé avec « oe ». Le fichier de correspondance se trouve dans le répertoire d'installation de Texpress, dans le fichier etc/unicode/base.map.
# # Le fichier suivant est utilisé pour étendre les mappages NFKD Unicode pour # caractères non spécifiés dans le standard. Le format du fichier est # une séquence de chiffres sous forme hex. Chaque numéro représente un seul code # point au format UTF-32. Le premier point de code est le point de code à mapper # ainsi que le deuxième point de code et les suivants représentent ce qu’il mappe. # 00C6 0041 0045 # Majuscule Latin AE -> A E 00E6 0061 0065 # Minuscule Latin ae -> a e 00D0 0044 # Majuscule Latin Eth -> D 00F0 0064 # Minuscule Latin eth -> d 00D8 004F # Majuscule Latin O barrée -> O 00F8 006F #Minuscule Latin o barrée -> o 00DE 0054 0068 # Majuscule Latin Thorn -> Th 00FE 0074 0068 # Minuscule Latin thorn -> th 0110 0044 # Majuscule Latin D barrée -> D 0111 0064 # Minuscule Latin d barrée -> d 0126 0048 # Majuscule Latin H barrée -> H 0127 0068 # Minuscule Latin h barrée -> h 0131 0069 # Minuscule Latin i sans point -> i 0138 006B # Minuscule Latin kra -> k 0141 004C # Majuscule Latin L barrée -> L 0142 006C # Minuscule Latin l barrée -> l 014A 004E # Majuscule Latin Eng -> N 014B 006E # Minuscule Latin eng -> n 0152 004F 0045 # Ligature Majuscule Latin OE -> O E 0153 006F 0065 # Ligature Minuscule Latin oe -> o e 0166 0054 # Majuscule Latin T barrée -> T 0167 0074 # Minuscule Latin t barrée -> t
Des mappages compatibles peuvent être ajoutés au fichier si nécessaire.
Note: Si le fichier est modifié, une réindexation complète du système est nécessaire pour que les nouveaux mappages soient utilisés pour calculer les termes d'index.
Si l'on considère la phrase française :
Sacré-Cœur est situé à Paris.
les termes d'index après non sensibilité à la casse et conversion en forme de base sont les suivants :
|
Terme d’index |
|---|
|
sacre |
|
coeur |
|
est |
|
situe |
|
a |
|
paris |
|
. |
Lorsqu'un enregistrement est sauvegardé dans EMu, tous les termes d'index ne sont plus sensibles à la casse et convertis dans leur forme de base avant l'indexation. De même, lorsqu'une recherche est effectuée, les termes de requête deviennent non sensibles à la casse et sont convertis dans leur forme de base avant que la recherche ne commence. Par conséquent, « coeur » ou « Cœur » ou même « COEUR » correspondra toujours au texte de la phrase française ci-dessus.
Phrase automatique
Les graphèmes Unicode sont répartis en trois catégories pour être utilisés dans EMu.
Les catégories sont :
| Catégorie | Description |
|---|---|
| combinaison |
Un graphème qui est une simple lettre ou un chiffre. Ce n'est pas un mot à part entière mais il nécessite d'autres caractères pour former des mots. Les lettres et les chiffres latins, arabes et hébreux en sont des exemples. |
| seul |
Un seul graphème est utilisé pour représenter un mot de base ou un sens. Les exemples sont les Kanji et les caractères de ponctuation. |
| rupture |
Un caractère qui délimite les mots, généralement un caractère d'espace. |
Observez le texte suivant :
香港 = "Hong Kong".
Les graphèmes et les catégories sont les suivants :
| Graphème | Catégorie |
|---|---|
|
香 |
seul |
|
港 |
seul |
|
|
rupture |
|
= |
seul |
|
|
rupture |
|
" |
seul |
|
H |
combinaison |
|
o |
combinaison |
|
n |
combinaison |
|
g |
combinaison |
|
|
rupture |
|
K |
combinaison |
|
o |
combinaison |
|
n |
combinaison |
|
g |
combinaison |
|
" |
seul |
|
. |
seul |
EMu utilise la catégorie pour déterminer un terme d'index. Chaque graphème seul est traité comme un élément d'index distinct, tandis que les combinaisons de graphèmes sont réunies pour former un « mot » jusqu'à un graphème de rupture ou seul. Un graphème de rupture n'est pas un terme d'indexation et est rejeté.
En général, une recherche par phrase doit être effectuée lorsque vous souhaitez trouver des enregistrements où une liste de termes d'index apparaît de manière séquentielle. Par exemple, pour trouver les deux caractères kanji 香港 (Hong Kong) l'un à côté de l'autre, la requête \"香 港\" peut être utilisée. Lorsqu'un graphème fait partie de la catégorie seul (comme les deux caractères kanji), le système connaît le terme d'index et est capable de les traiter comme une phrase à condition de ne pas trouver de caractère rupture. En réalité, EMu traite une combinaison de graphèmes combinaison et seul comme une phrase sans avoir besoin d'opérateur de phrase jusqu'à trouver un graphème de rupture. Ce processus est connu sous le nom de phrase automatique.
La phrase automatique signifie que la requête 香港 est équivalente à \"香港\" sans qu'il soit nécessaire d'ajouter de guillemets ou d'espace. Autre exemple, une adresse e-mail comme fred@global.com. Dans ce cas, les termes d'index fred, @, global, ., com doivent être localisés séquentiellement. La phrase automatique vous permet effectivement de saisir des termes non séparés par des espaces et EMu retrouvera les enregistrements où les termes sont adjacents. Si vous ne voulez pas que les termes apparaissent l'un à côté de l'autre, par exemple si vous voulez trouver 香 (parfumé) 港 (port), il suffit de placer un espace entre les deux caractères kanji pour désactiver la phrase automatique.
Collation
La collation est le terme général pour le processus de détermination de l'ordre du tri des chaînes de caractères. EMu 5.0 et suivants utilisent la Default Unicode Collation Element Table (DUCET), telle que définie dans le standard Unicode 8.0, pour déterminer comment le texte doit être trié. DUCET fournit un mécanisme de locales indépendant pour trier les valeurs.
Si vous êtes intéressé par l'ordre utilisé par DUCET, consultez le tableau de collation Unicode.

